We are pleased to announce the third Open Publishing Fest (June 3-14), a decentralized public event that brings together communities supporting open source software, open content, and open publishing models. This year's fest will be held during two weeks in June, featuring discussions, demos, and performances that showcase our paths toward a more open world.
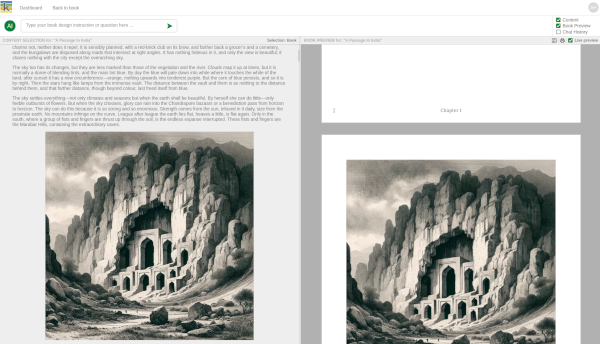
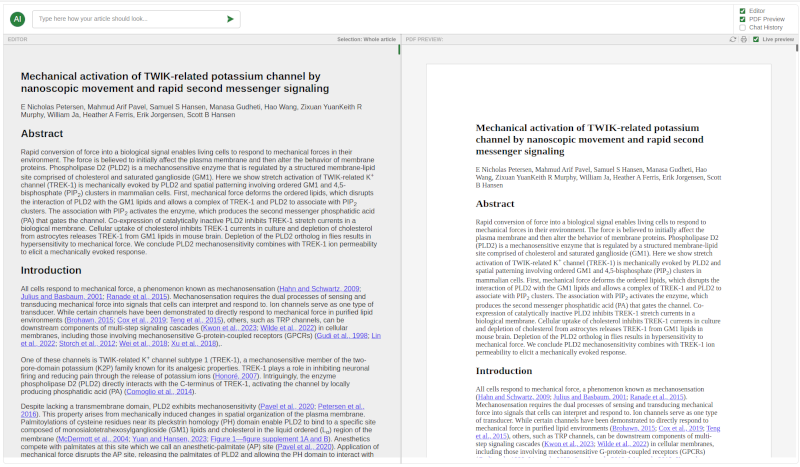
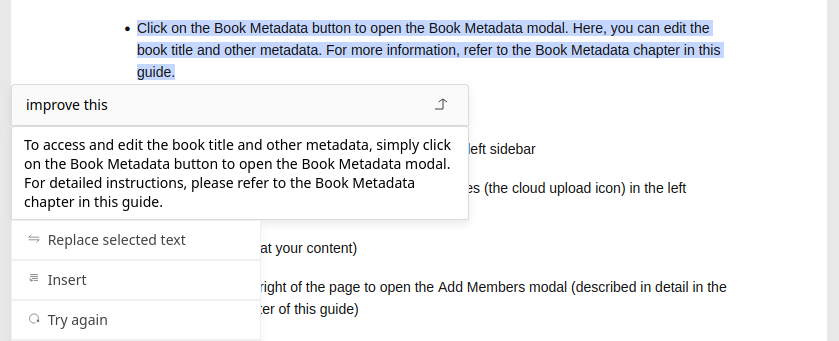
We're excited to bring you a groundbreaking innovation that's set to
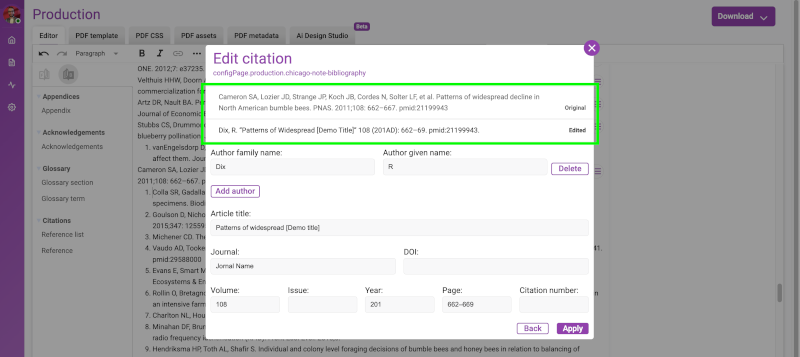
transform the way we think about PDF production: the Kotahi AI PDF
Designer. This revolutionary tool is not just an advancement; it's a
complete reimagining of the PDF design process, tailored to meet the
needs of today's publishers, researchers, and content creators.
We've recently enhanced the [Ketty](https://ketty.community/?ref=robotscooking.com) book production platform, which is 100% open source, by integrating an AI Assistant.
A new report released this week from Open Research Europe (ORE) provides a glowing review of Kotahi, finding it to be "a cutting-edge platform for scholarly publishing that can accommodate various end-to-end publishing workflows."
Amnet and Coko are celebrating the launch of Nvcleus, a cost-effective journal solution based on the Kotahi platform, at the London Book Fair. This partnership has successfully developed an innovative approach to journal publishing, focusing on affordability and openness for publishers.
FOR IMMEDIATE RELEASE
Mellon Foundation Grants $595,000 to Support Coko Development
San Francisco, CA - Coko is delighted to announce that the Andrew W. Mellon Foundation has awarded a grant of $595,000 over 2 years to support the continued development of [Ketida](https://ketida.community) (formerly called Editoria), the innovative web-based book production platform.
Recently, a team of technologists from across the globe came together in New Zealand to brainstorm how to integrate AI into the peer review process using Kotahi responsibly. We recognize the potential benefits that AI can bring, such as increased efficiency and accuracy, but we also acknowledge the need to be thoughtful about how we implement this technology.
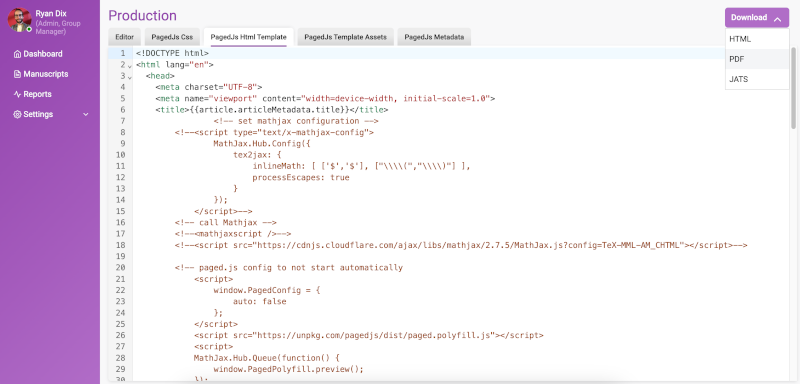
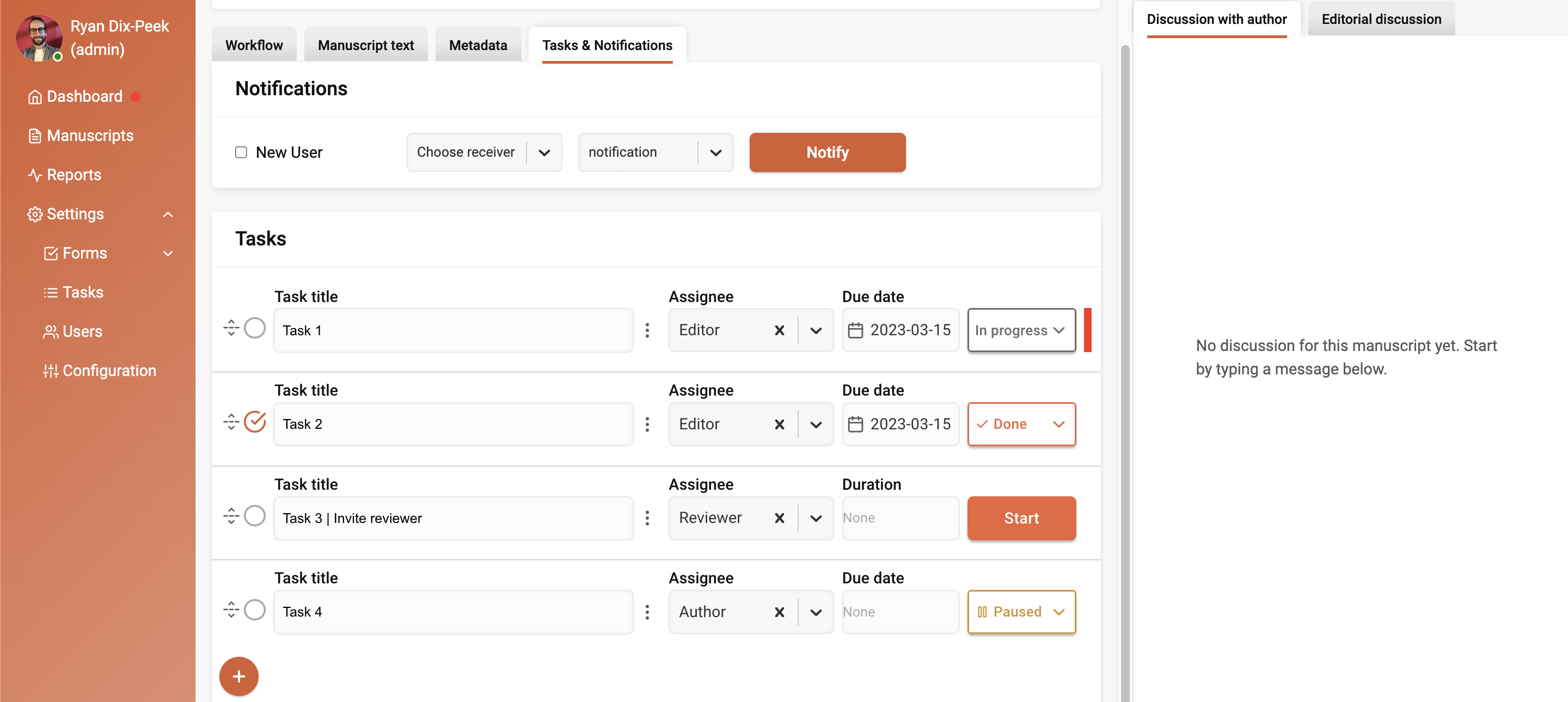
Kotahi, an open-source, web-based platform for managing scholarly publications, has released its latest version, Kotahi 1.6. This new version brings a number of enhancements and bug fixes, as well as a plugin architecture for handling both Wax and generic plugins.
Stay ahead of the game with Coko's cutting-edge AI technology. Our new subsystem in CokoDocs, Kotahi, and Ketida is designed to empower publishing partners and revolutionise their workflows.
Coko and the Women in Tech Collectives are proud to announce a new partnership! The Women in Tech Collectives from India is a small community led by women tech enthusiasts…